WordPressでrobots.txtを設定する
公開日:2014年6月5日
最終更新日:2014年7月13日
robots.txtは、特定のファイルやディレクトリをアクセスされないようにブロックする目的で使われます。特にクローラーに対して価値のないURLをクロールさせないことは、SEOにも有利に働きます。そのrobots.txtをWordPressサイトで利用する方法を解説します。
【コンテンツ】
【記事執筆時の環境】
WordPress 3.9.1
WordPressでのrobots.txt自動生成
WordPressではファイルとしてrobots.txtをあらかじめ作成しているわけではなく、アクセスがあったときに動的に生成します。
したがって、WordPressをインストールしたディレクトリのどこを探してもrobots.txtは見つかりませんが、ブラウザのアドレスバーに「http://ドメイン/robots.txt」と入力すると、以下のように表示されます。
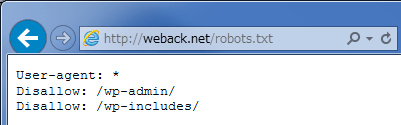
上記はWordPressの設定がデフォルトでの表示ですが、インストールしているプラグインによっては内容が変わることがあります。
また管理画面メニューの[設定]-[表示設定]で、
[検索エンジンがサイトをインデックスしないようにする]にチェックが入っていると、以下の表示になります。
|
1 2 |
User-agent: * Disallow: / |
これはサイト全体がアクセス禁止になっていることを示します。
【注意!】
- パーマリンク設定がデフォルトのままだとrobots.txtは生成されず、アクセスした時に404エラーとなります。
- WordPressをドメインのルートディレクトリでなくサブディレクトリにインストールしている場合も、robots.txtにはアクセスできません。もともとrobots.txtはルートドメインに置かなければ無効です。
robots.txtを自分で作成する
「robots.txt」という名前のテキストファイルを作成し、ルートドメインにアップロードします。
アップロードしたrobots.txtが優先されます。
基本的な記述方法としては、「User-agent」と「Disallow or Allow」をセットで指定します。
また「Sitemap」でサイトマップを指定することもできます。
例えばWordPressのデフォルト設定に加え、Google画像検索をすべてブロックしサイトマップを指定したい場合は、以下のように記述します。
|
1 2 3 4 5 6 7 8 |
User-agent: * Disallow: /wp-admin/ Disallow: /wp-includes/ User-agent: Googlebot-Image Disallow: / Sitemap: https://weback.net/sitemap_index.xml |
ウェブマスターツールでの動作確認
robots.txtは、思い通りの動作になっているかウェブマスターツールで確認することができます。
該当するWebサイトのダッシュボードから、[クロール]-[ブロックされたURL]を選択します。
robots.txtの内容とテストするURLを入力し、User-agentsを指定して[テスト]ボタンをクリックします。

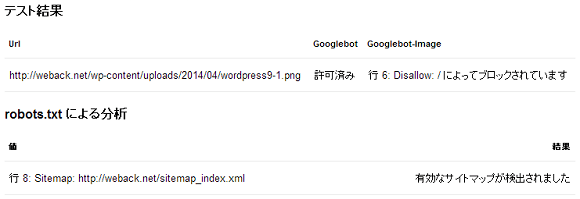
画面の下にテスト結果が表示されますので確認します。
この例では「User-agent: Googlebot-Image」でURLがブロックされ、有効なサイトマップが検出されましたので、正しく動作していると確認できました。
スポンサーリンク





